운영체제 정리 - CPU Scheduling
Basic Concepts
- CPU Utilization을 극대화하기 위해서는 CPU가 노는 시간이 없도록 해야함
- CPU burst Process와 I/O burst Process가 번갈아 가며 실행됨
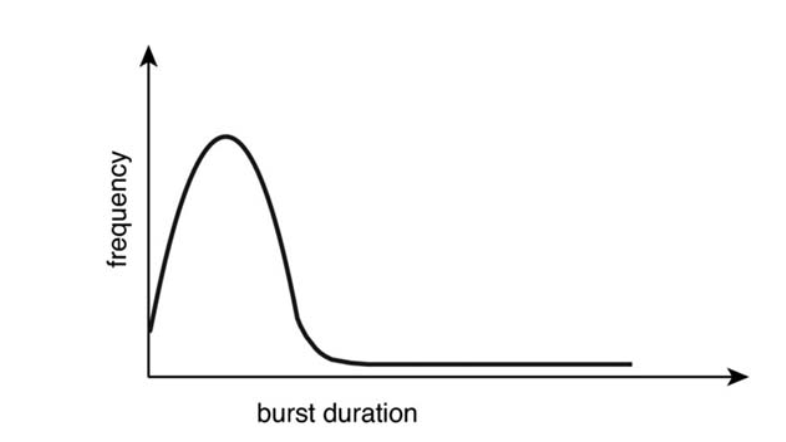
burst duration에 따른 빈도수 그래프
- I/O burst Process가 훨씬 많음을 보임 => 이런 Process들을 잘 스케줄링하여 CPU가 노는 시간을 최소화 하도록 해야함
CPU Schedular
- ready queue에 있는 프로세스를 선택하고 CPU자원을 할당
Dispatcher
- context switch가 일어날 때 이를 처리하는 모듈
- dispatcher가 cpu를 중단 시키고 다음 프로세스가 실행될 때까지의 시간을 dispatch latency라함
Scheduling 평가요소
CPU utilization: cpu가 활용되는 정도, %로 나타냄
Throughput: 시간당 프로세스 처리량, scheduling 방법보단 프로세스 종류에 영향을 많이 받음
Turnaround time: 특정 프로세스가 대기하는 시간 + 실행시간 즉, 총 처리 시간
Waiting Time: 특정 프로세스가 대기하는 시간
Response Time: 특정 프로세스가ready queue에 올라가 처음 running되기 까지의 시간
Scheduling 알고리즘
FCFS(First-Come, First-Served)

FCFS
- 가장 단순한 알고리즘으로 먼저 queue에 들어온 순서대로 실행
- convoy effect가 발생할 수 있음
- Nonpreemptive함
**convoy effect: **긴 실행시간을 가진 작업이 다른 짧은 실행 시간을 가진 작업을 block시키는 것
SJF(Shortest-Job-First)
 <p align="center" style=" font-size: 12px; color: #999;">SJF</p>
<p align="center" style=" font-size: 12px; color: #999;">SJF</p>
- 실행시간(CPU burst time)이 짧은 순으로 실행
- 평균 대기 시간이 가장 짧은 최적의 알고리즘
- CPU Burst를 예측해야되기 때문에 실제로는 적용이 어려움
선점 알고리즘(Shortest-Remaining-Time-First)
- SJF는 비선점 알고리즘으로 실행 중인 작업과는 비교하지 않지만
- SRTF는 선점 알고리즘으로 새로 들어온 작업의 실행시간이 실행 중인 작업의 남은 시간보다 작으면 선점한다
RR(Round-Robin)
- 정해진 실행시간을 각 작업들이 나눠서 사용하는 방법, 이 정해진 시간을 time quantum이라 한다
Time Quantum
- 만약 time quantum이 모든 작업의 실행시간보다 크다면 FCFS와 같다
- 만약 time quantum이 너무 작다면 지나친 context switch가 일어나 성능이 저하된다
=> 따라서 적당한 time quantum size가 필요하다

time quantum = 4 인 RR
- 일반적으로, waiting time과 turnaround time은 SJF에 비해 떨어지지만 response time은 더 좋다
Priority
- 우선순위를 부여하여 순서를 정하는 방법
- SJF도 실행시간을 기준으로 우선순위를 부여했다고 볼 수 있다
문제점 및 해결방법
- 낮은 우선순위가 실행되지 않는 starvation이 발생할 수 있음
- 오래 대기한 작업의 우선순위를 높이는 aging을 사용하거나
- 일정 실행시간이 보장되는 RR을 결합시켜 사용
Priority와 RR의 조합
- _이 부분이 시험문제에 나와서 약간의 논란이 있었는데 포인트는 ‘RR이 priority를 무시하고 선점할 수 있느냐 아니면 RR이어도 priority가 더 우선이다’ 이었다. 배울 때는 같은 우선순위만 RR을 적용하는 것이었는데 시험문제에서는 같은 우선순위인 것이 없는 채로 RR을 결합한 문제 나왔고 따로 명시가 되어있지 않은채로 헷갈리게 나왔다. _ 이에 대해 GPT에게 물어보니 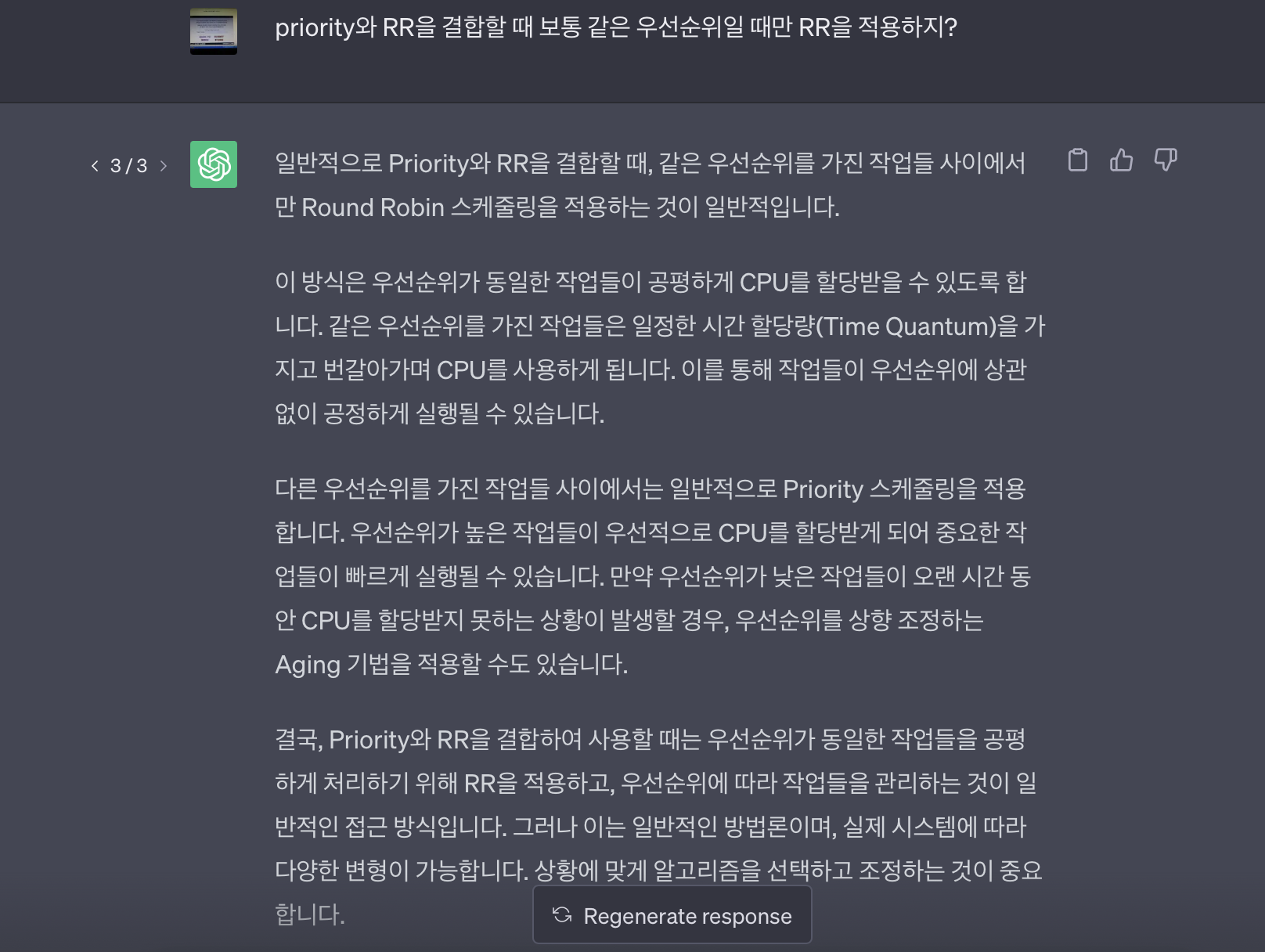
그런데 이방법을 사용하는 이유 자체가 starvation을 줄이기 위해서 였는데 같은 우선순위에서만 적용하면 starvation문제가 여전히 해결되지 않는 것 같아 다시 물어봤더니
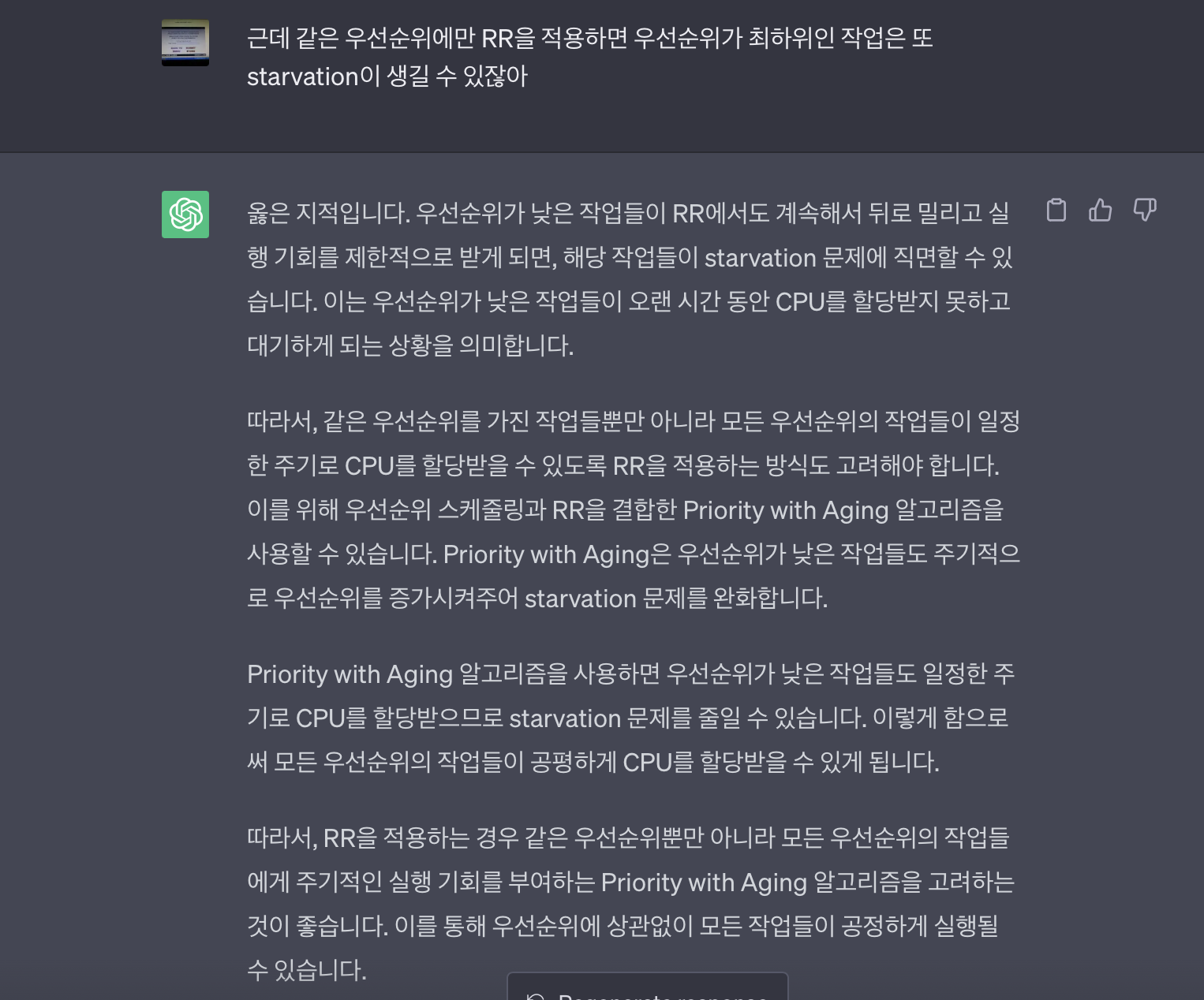 라고한다.
라고한다.
결론적으로, priority와 RR의 결합은 일반적으로는 같은 우선순위에 대해서만 RR을 적용시키고 추가적으로 aging알고리즘도 함께 결합하여 starvation을 해결할 수 있다고 보면 될 것 같다.
Multilevel Queue
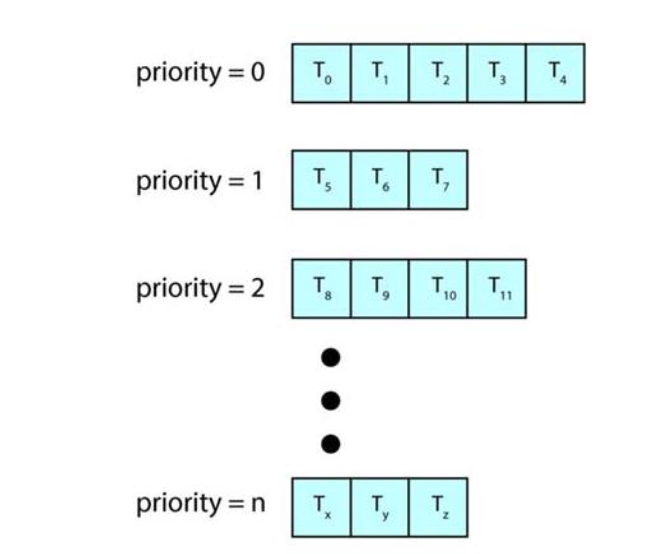
multilevel queue
- ready queue를 여러개로 나누어 큐 자체에 우선순위를 부여하여 작업을 실행시키는 방법
- 각각의 큐는 상황에 맞게 스케줄링 기법을 선택할 수 있지만 일반적으로 RR을 사용
- 모든 큐가 RR을 사용하면 앞의 priority & RR의 combining한 기법을 구현한 것임
- 우선순위 기법을 베이스로 했기 때문에 starvation이 생길 수 있음
Multilevel Feedback Queue
- multilevel queue에서 starvation을 방지하기 위한 방법
- 낮은 priority의 queue에 너무 오래 있다면 더 높은 우선순위 queue로 옮김, 그리고 이것이 곧 aging 기법
Thread Scheduling
PCS(Process-contention Scope)
- 유저 스레드가 LWP를 점유하기 위한 경쟁의 범위(in process)
SCS(System-contention Scope)
- 커널 스레드가 CPU를 점유하기 위한 경쟁의 범위(in System)
Multi-Processor Scheduling
Asymmetric/ Symmetric multiprocessing
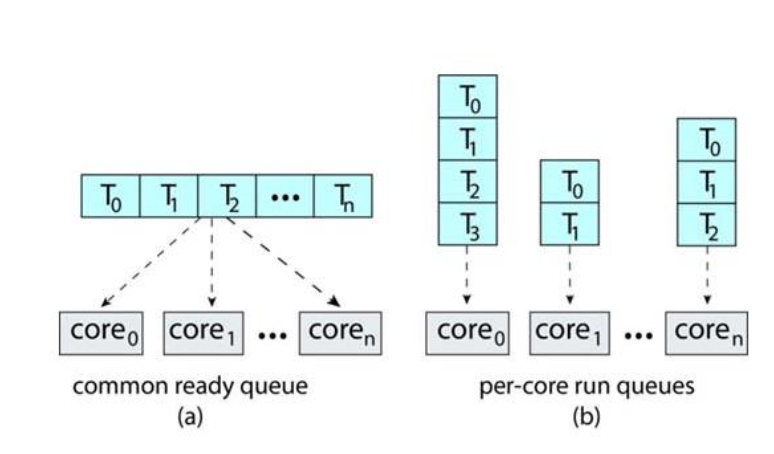
multiple-processor에서의 두 가지 전략
Asymmetric multiprocessing: 하나의 프로세서가 모든 스케줄링을 관리하는 것, 하나의 공통 큐를 가짐
symmetric multiprocessing: 각각의 프로세서가 자신의 큐에서 스케줄링 하는 것, 각자의 큐를 가짐
Multicore Processor
- 최근에는 더 빠르고 전력소모가 적은 멀티코어를 많이 사용한다
- 동시에 각각의 코어에 내장된 하드웨어 스레드도 많이 사용한다
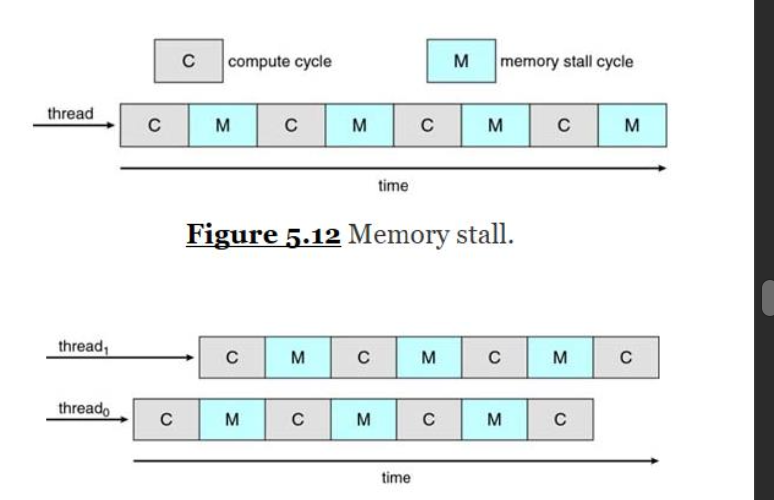
Multithreaded multicore system을 이용하여 Memory stall을 해결
=> 이렇게 하나의 코어 내에 동시에 여러개의 스레드가 실행되어 성능을 향상시킬 수 있다. 이를 hyper-threading(Intel용어) 또는 Simultaneous Multithreading(AMD용어)이라 부른다
Two levels of scheduling
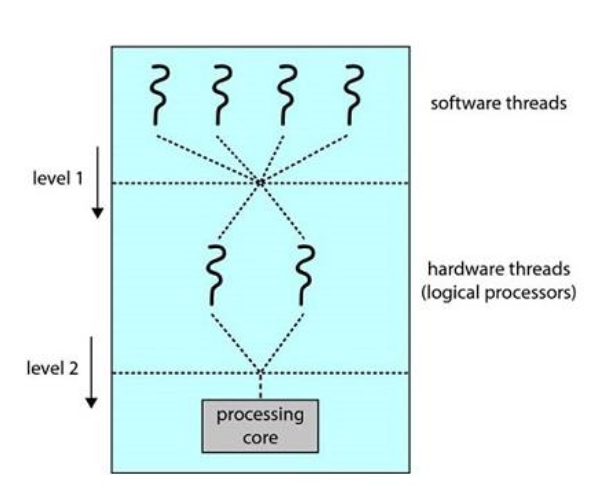
Two levels of scheduling
- Multithreaded multicore processor는 물리적 하드웨어가 존재하기 때문에 두 번의 schduling을 거쳐야 한다.
- level1이 기존의 thread를 스케줄링하는 것이고
- level2가 어떤 hardware thread를 사용할지 스케줄링 하는 것이다.
Load Balancing
- SMP 시스템을 이용할 때 모든 CPU가 고루 사용되어야 하는데, 이를 Load Balancing이라 한다
push migration: 밸런스를 맞추기 위해 overload된 CPU에서 idle CPU로 작업을 분산 시키는 것
pull migration: idle CPU에서 busy processor의 작업을 가져오는 것
Processor Affinity
- 프로세스가 실행되고 있던 프로세서에 친화성을 가지는 것(캐시 메모리 활용을 위해)
soft affinity: 원래 프로세서에서 실행되기를 유지하려고는 하지만, load balancing의 이유로 다른 프로세서로 갈 수 있음
hard affinity: 시스템 콜을 사용하여 프로세스를 실행할 CPU에 바인딩 되는 경우
NUMA
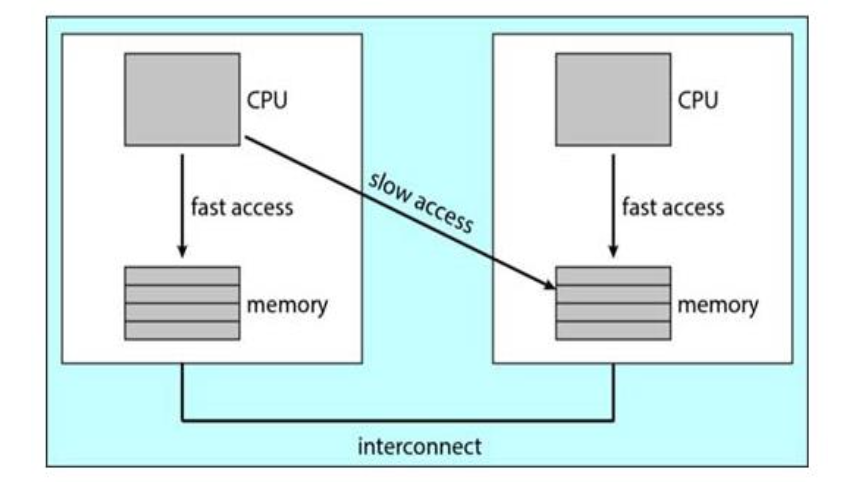
NUMA 구조
- NUMA의 구조자체가 Affinity가 보장이 되는 구조임
Heterogeneous Multiprocessing
- 같은 코어 구조를 가지고 있지만 전력소모와 clock speed에 차이를 가지는 구조 ex) ARM processor의 big.LITTLE 높은 성능이 요구되는 작업에는 big core를 성능보단 낮은 전력 소모가 요구되는 작업에는 little core를 사용
Real-Time CPU Scheduling
Soft read-time vs Hard real-time
soft real-time: deadline을 보장하려고 노력하는 시스템 hard real-time: deadline이 보장되는 시스템
Latency의 최소화
- real-time은 반응속도가 매우 중요하여 Latency를 최소화 시키는 것이 관건이다
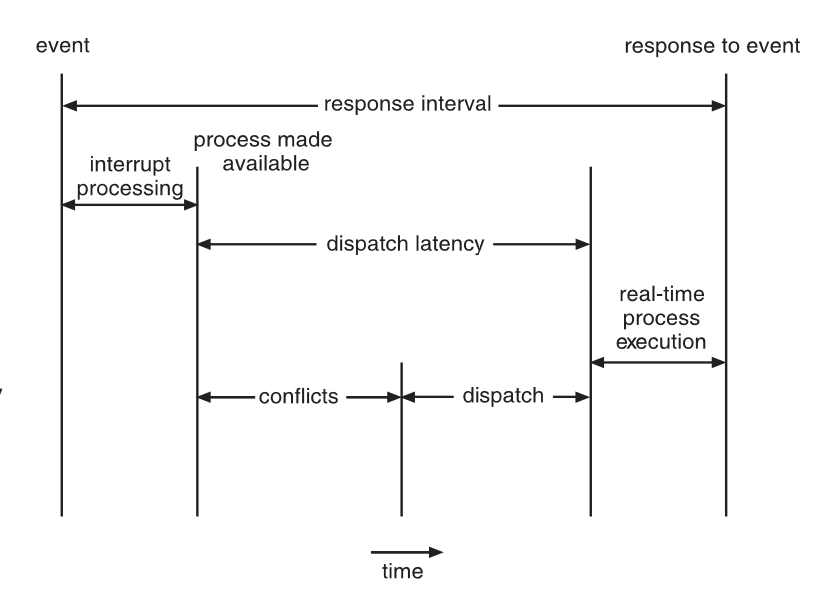
event 처리 과정
Event latency: 이벤트가 일어나고 이 이벤트에 대한 반응이 일어나기 까지의 시간
Interrupt latency: 인터럽트가 발생하고 인터럽트 서비스 루틴이 시작 될 때까지의 시간
Dispatch latency: 현재 실행중인 프로세스를 해제하고 새로운 프로세스로 전환 시키기까지의 시간, 서비스 루틴까지의 처리가 완료된 뒤에 일어남
=> 반응시간을 빠르게 하기 위해 event latency를 최소화 시키기 위해서는 interrupt latency와 Dispatch latency를 최소화 해야한다
priority-based Scheduling
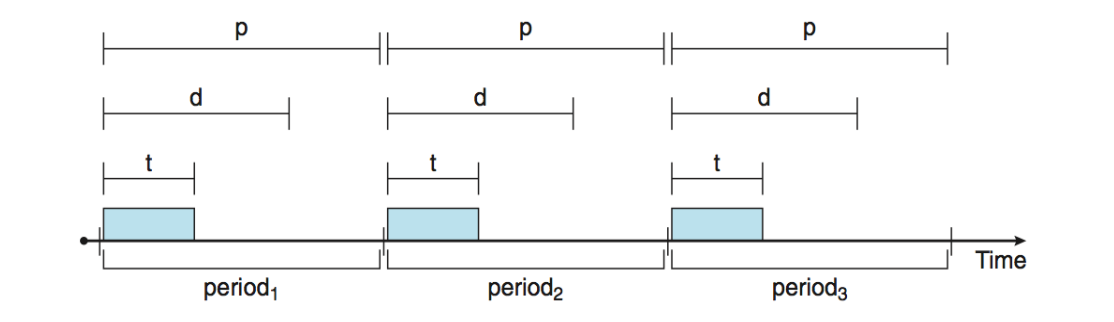
- real-time scheduling은 선점적이고 우선순위를 기반으로 한 스케줄링 기법을 사용해야한다
- 주기적으로 발생하는 작업을 먼저 고려하여, 이 작업들을 예측 가능한 주기와 패턴 내에서 처리하기 위한 방법을 사용한다.
- 이때 사용하는 개념이 각각 time t, deadline d, period p이고 0 ≤ t ≤ d ≤ p
- 하나의 주기에 데드라인을 두고 그안에 작업을 실행해야함
Rate Monotonic
- 주기가 짧은(자주 실행해야 하는)작업이 우선순위가 높도록 하는 방법
- 시간이 급한 것을 먼저 처리하므로 deadline을 더 잘 지킬 수 있음
ex) p1 = 50, t1=20 / p2=100, t2=35 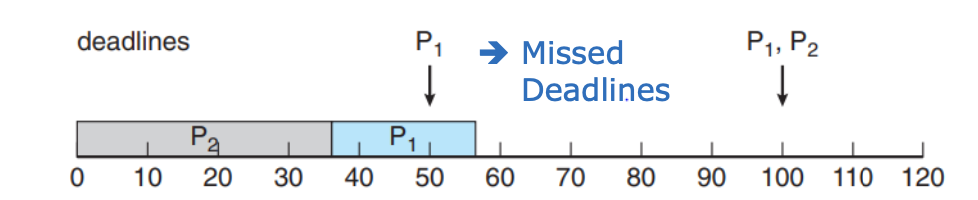
Rate Montonic X

Rate Montonic O
- 같은 조건에서 Rate Montonic 스케줄링을 적용한 것이 더 안정적임을 볼 수 있음
- 스케줄링하는 프로세스의 개수가 N 일때 N(2^(1/N) - 1) 보다 CPU Utilization이 작으면 deadline을 넘지 않음
- 이경우에는 약 83% > 75%이므로 가능
EDF(Earliest Deadline First)
- 각 주기의 시작마다 deadline을 비교하여 우선순위를 정하는 방법
- CPU Utilization이 100%보다 작기만 하면 된다
Propotional Share
- 각 프로세스의 할당량만큼 작업시간을 부여하는 방식, 주기적인 방식이 아님
- 만약 전체 시간을 넘는 요청이 추가로 들어오면 거절한다.