운영체제 정리 - Main Memory
배경
- 프로그램이 실행되려면 2차 저장장치에 있는 프로그램을 memory로 가져와야한다
- 2차 저장장치 보단 1차 저장장치인 메인 메모리가, 그보다는 register가 접근 속도가 빠르다(register는 one CPU clock)
- register와 메인 메모리 사이에 Cache가 존재하여 이 간극을 줄여준다
Base and Limit Registers
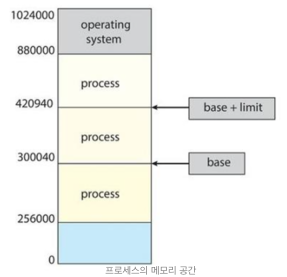
- 프로세스는 고유 메모리 공간을 갖는다
- base(relocation) register와 limit register가 이 공간을 정의한다
- user mode에서는 메모리 접근 시 이 공간을 넘지 않도록 항상 확인해야한다
Address Binding
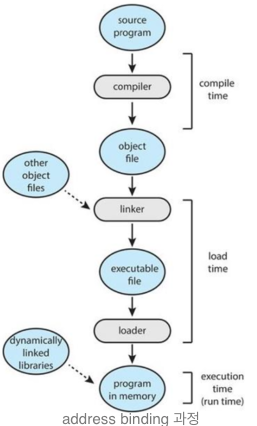
- 컴파일러가 소스코드를 컴파일하여 relocatable address(상대 주소)정보가 있는 object 파일로 변환시킨다
- linker가 여러 object 파일들을 합쳐 **absolute address(절대 주소) **를 부여하고(재배치는 link, load과정에 걸쳐 일어난다) 하나의 single binary executable file로 만든다
- 이를 메모리에 load하여 프로그램을 실행하는 것이고, 필요 시 동적으로 DLL이 로드되어 같이 실행될 수 있다. (DLL이 뭔지는 조금 뒤에 설명)
⚠ 주의 absolute address와 physical address는 다른 개념이며 가상 주소를 사용하는 경우 absolute address는 logical address이다 관련 stack overflow 질문
address binding 종류
Complie time binding
- 컴파일 시점에 주소가 결정 되는 방법
- 과거에 돌아가는 프로그램이 1개일 때 많이 사용, 임베디드 시스템에서는 지금도 사용
Load time binding
- 메모리에 load할 때 주소가 결정되는 방법
- linker에서 수행한 재배치 정보를 토대로 메모리 오프셋, 세그먼트의 크기 등을 고려하여 loader가 실제로 메모리 주소에 배치
- 로딩할 때마다 주소가 바뀌므로 로딩시간이 오래걸림
Execution time binding
- 실제 실행 전까지 상대 주소로 두는 방법
- MMU의 지원이 필요
- 메모리 로드 시간이 빨라짐
Logical vs. Physical Address Space
Logical address(= virtual address): CPU에서 다루는 가상의 주소
Physical address: 실제 메모리 주소로 memory-address register(MAR)에 저장됨
+ 실행시간에 physical memory가 결정되는 Execution time binding만 논리 주소를 사용한다
MMU와 Dynamic Relocation
Memory-Management Unit(MMU): 실행 시간에 논리 주소를 물리주소로 변환시키는 장치 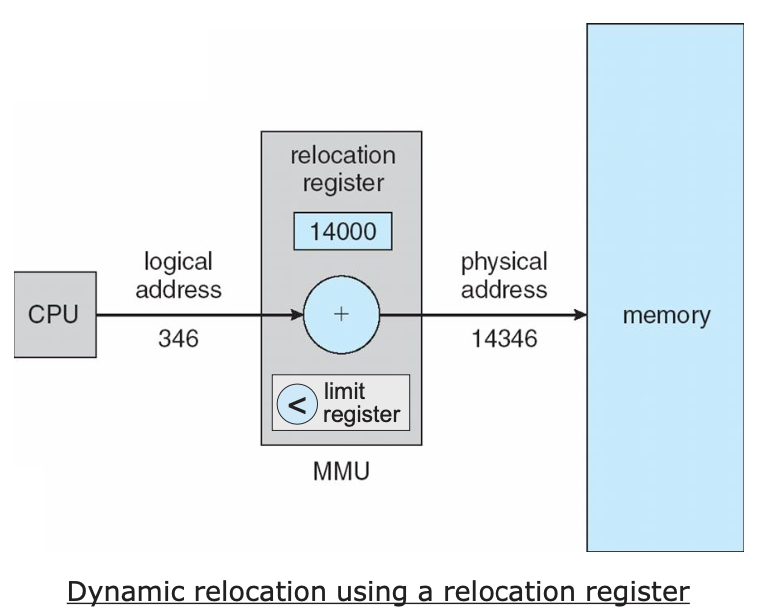
- relocation register 값과 logical address 값을 더하여 물리 주소를 결정
- logical address가 limit register를 넘기면 안됨
Dynamic Loading과 Dynamic Linking
Dynamic Loading
- 평소 잘 사용되지 않는 루틴(예외 처리 등)을 동적으로 로딩
- 메모리 공간을 효율적으로 사용
- 운영체제의 지원이 크게 필요하지 않음
Dynamic Linking
- 실행 시에 필요한 라이브러리를 동적으로 Linking
- 이때 동적으로 Linking되는 라이브러리가 Dynamically linked libraries(DLLs)
- 운영체제의 지원을 받아 여러 프로그램에서 공유하여 사용가능하여 메모리 효율을 높임
Contiguous Memory Allocation
- 메모리를 사용하는 부분은 크게 OS와 Processees로 나뉨
- Process끼리는 서로 침범하면 안되고, 특히 OS 코드나 데이터는 바뀌면 안됨
- 동시에 메모리는 한정되어 있기 때문에 효율적으로 사용해야함
- 그래서 사용하는 방법 중 하나가 연속적으로 메모리를 할당하는** Contiguous Memory Allocation **
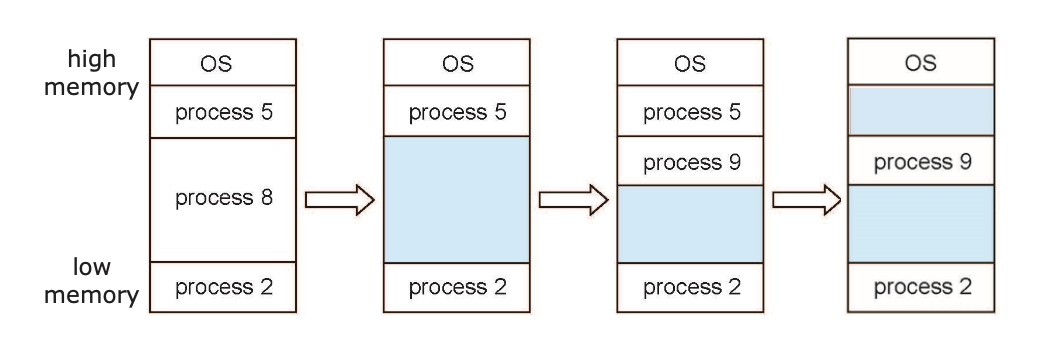
그런데 이 방법을 사용하다 보면 프로세스가 중간에 종료되어 사용가능한 메모리 Hole이 생기기 때문에 메모리를 효율적으로 사용하려면 이 hole을 최대한 메우는 것이 좋다.
Dynamic Storage-Allocation Problem
이 hole을 메우기 위해 크게 3가지 방법이 있는데 이를 적절히 사용하는 것이 좋다
first-fit: 충분한 공간(hole)을 찾으면 바로 할당하는 방법 best-fit: 충분한 공간 중 필요한 메모리 크기와 가장 딱 맞는 공간에 할당하는 방법 worst-fit: 공간 중 가장 큰 공간에 할당하는 방법
메모리 효율은 best-fit이 속도는 first-fit이 가장 좋다
단편화(Fragmentation)
External Fragmentation: 프로세스에 할당되지 않고 비어있는 hole
Internam Fragmentation: 프로세스에 할당되었지만 필요 이상으로 할당되어 사용되지 않는 메모리
Contiguous memory allocation에서 보편적인 first-fit 방법을 사용할 때 약 3분의1 정도의 메모리가 외부 단편화에 의해 사용불가함, 이를 해결하기위한 방법으로 Compaction이 있음
Compaction
- 여러 나눠진 hole을 하나의 충분한 공간으로 합치는 방법
- Execution time binding에서만 가능
- 하지만 이 방법도 비용이 비쌈
🌟Paging
- 미리 page라는 가상의 단위로 메모리 공간을 나누어 할당하는 방법
- 논리적인 메모리 단위는 page, 물리적인 단위는 frame이라 하고 크기는 1:1로 같다
- 논리적 주소를 물리적 주소로 변환할 때 Page table을 이용한다
- 외부 단편화는 없지만 내부 단편화가 있을 수 있다
page table을 이용한 변환
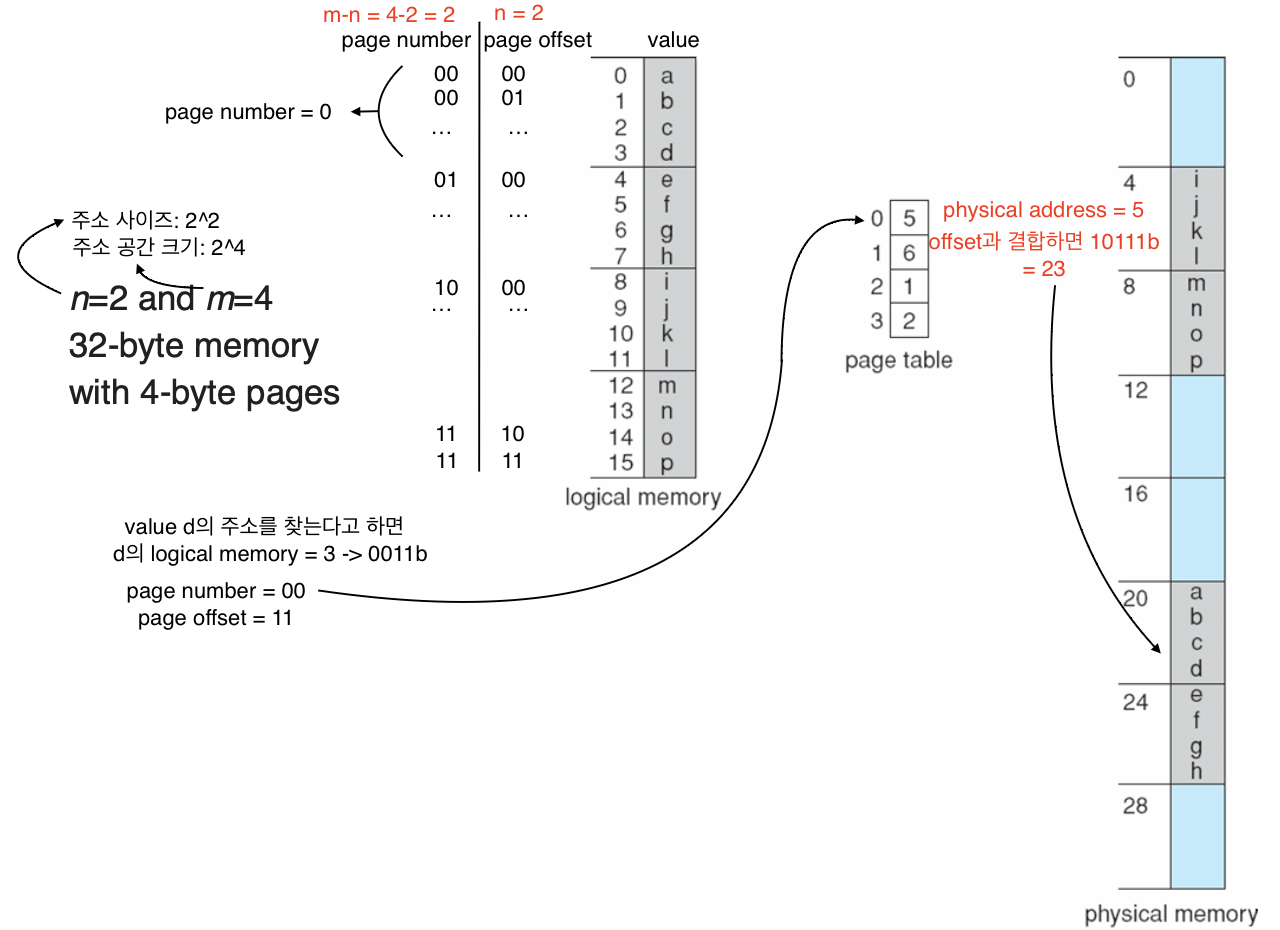
논리적 주소를 address space와 page size에 따라 page number, page offset를 나눌 수 있고 이를 page table의 물리적 주소와 나눴던 offset과 결합하면 실제 물리주소를 찾을 수 있다.
paging의 내부 단편화
- Page size = 2048 bytes
- process size = 72766 bytes (35 pages + 1086 bytes)
- 2048 - 1086 = 962 bytes 만큼의 내부 단편화가 발생
- 최악의 경우 1 frame - 1 byte 만큼 발생
- 평균 1/2 frame size
바람직한 page(frame) size
- 내부 단편화를 줄이려면 page size를 작게 하면됨
- 하지만 작게할수록 page table의 크기가 반비례해서 늘어남
- 그래서 보통 적당한 크기로 4KB or 8KB로 사용
Page table 접근과 TLB
page-table base register(PTBR): page table의 주소를 갖는 레지스터 page-table length register(PTLR): page table의 크기를 갖는 레지스터
page table을 이용하여 메모리에 접근하려면 메모리에 두 번 접근을 해야한다 page table에 접근할 때 1번, 실제 주소에 접근할 때 2번 이를 줄이기 위해서 TLB를 사용한다
Translation look-aside buffers(TLBs)
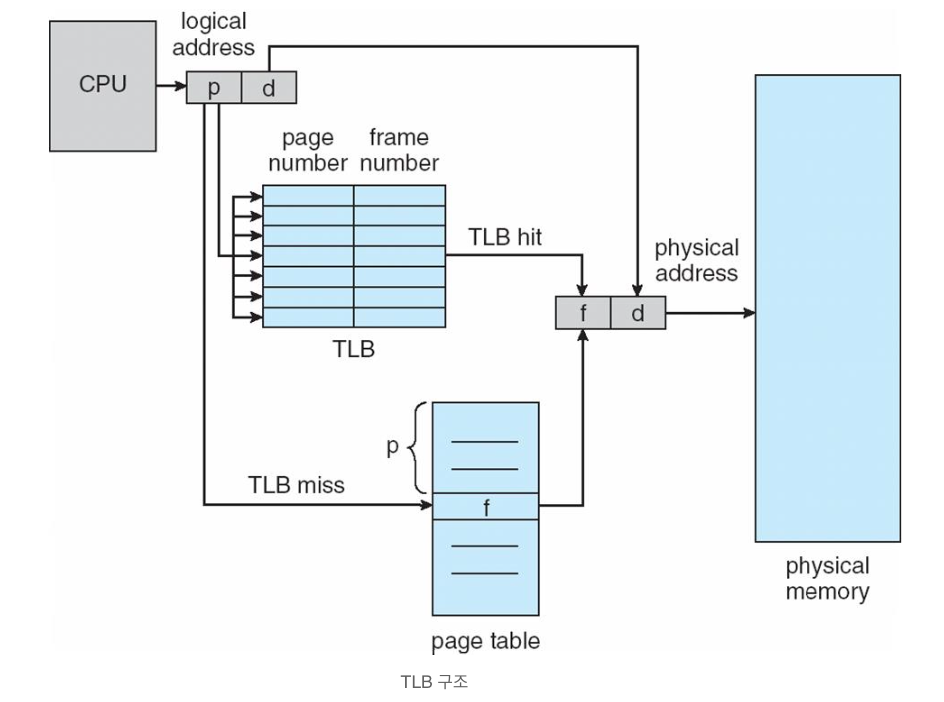
- TLB는 CPU에 근접하게 위치한 하드웨어 장치로 레지스터와 같은 접근 속도를 가진다(caching)
- 병렬적으로 주소를 찾는다
- TLB에 찾는 주소가 있으면 TLB hit 없으면 TLB miss이다
- TLB의 공간 크기는 메모리보다 작기 때문에 스케줄링이 필요하고, 커널 등 중요한 정보는 고정되어 있다(wired down)
- 프로세스를 식별할 수 있는 ASIDs(Address-Space Identifiers)가 TLB에 저장되어 교체를 덜 일어나게 한다
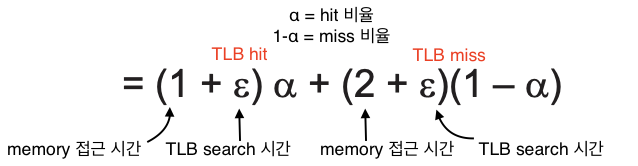
Effective Access Time(EAT)
평균적인 메모리 접근 시간 식을 EAT라 하고 아래는 메모리 접근 시간을 1이라고 했을 때 EAT 식이다
Valid-invalid Bit
메모리 보호를 위해 page table의 엔트리마다 valid-invalid 비트로 주소가 해당 프로세스 내에 있는지의 여부를 알려준다
Page Table 구조
Hierarchical Paging
- 계층적 구조로 page table이 존재
- 간단한 two-level 구조의 경우 outer page table과 innter page table이 1개씩 존재
- 32비트 컴퓨터의 경우 page offset이 12비트, page number가 각각 10비트씩 차지
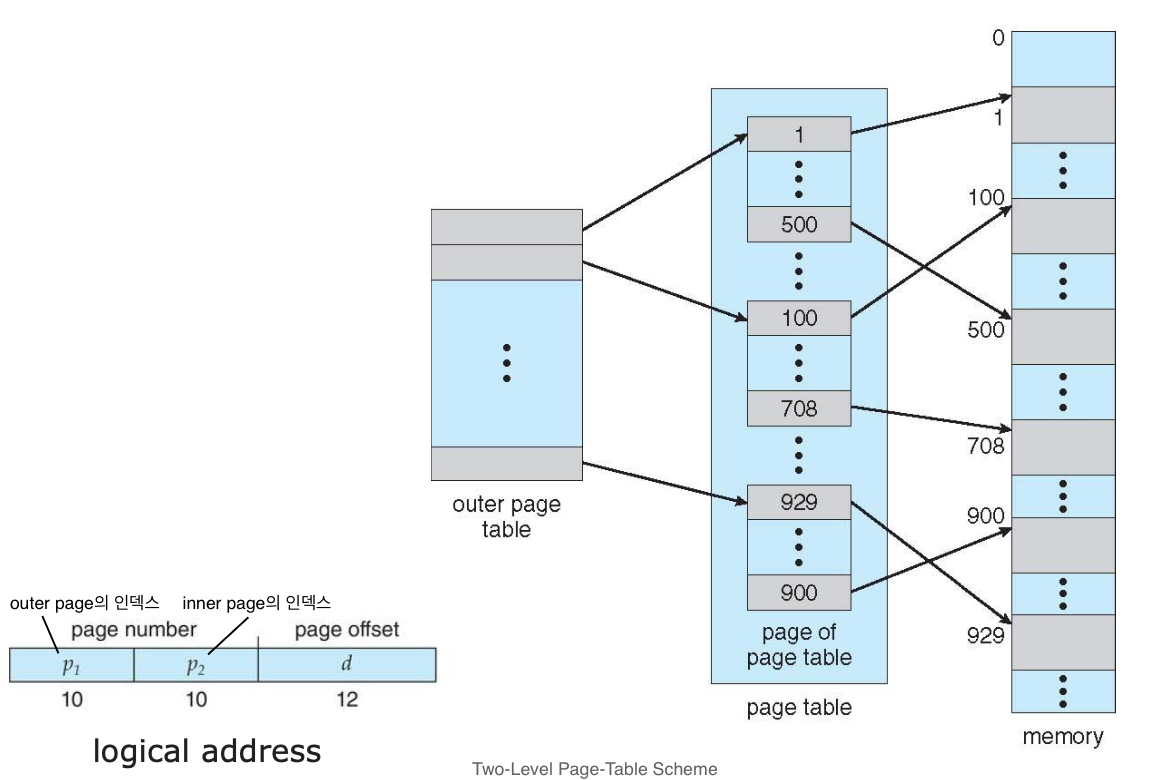
32비트이하의 컴퓨터의 경우에는 적합하지만 그 이상의 비트를 가지는 컴퓨터에는 page table의 계층이 늘어나 한 번 접근하는데 더 많은 메모리 접근을 필요로 하기 때문에 부적합하다
Hashed page tables
- 논리 주소의 page number를 hash를 통해 물리 주소로 바꾸는 방법
- 속도가 빨라 32비트를 넘는 컴퓨터에서 주로 사용
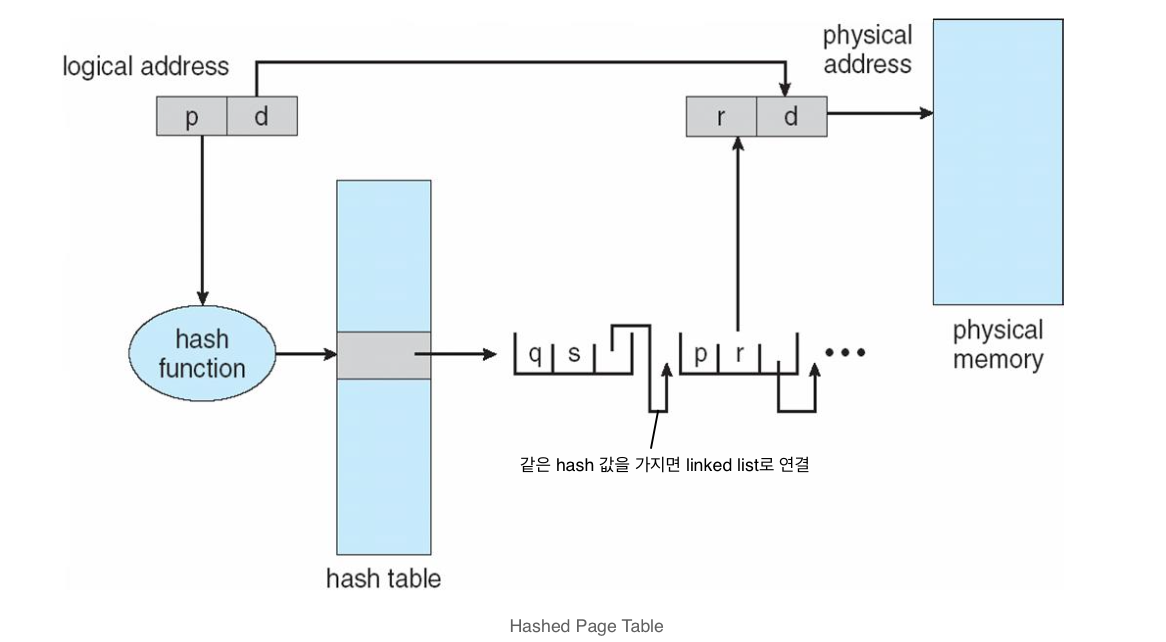
+Clustered page tables hash와 유사하지만 1개의 엔트리에 한번에 여러개가 매핑될 수 있는 방법 주소가 많이 흩어져 있을 때 유리하다
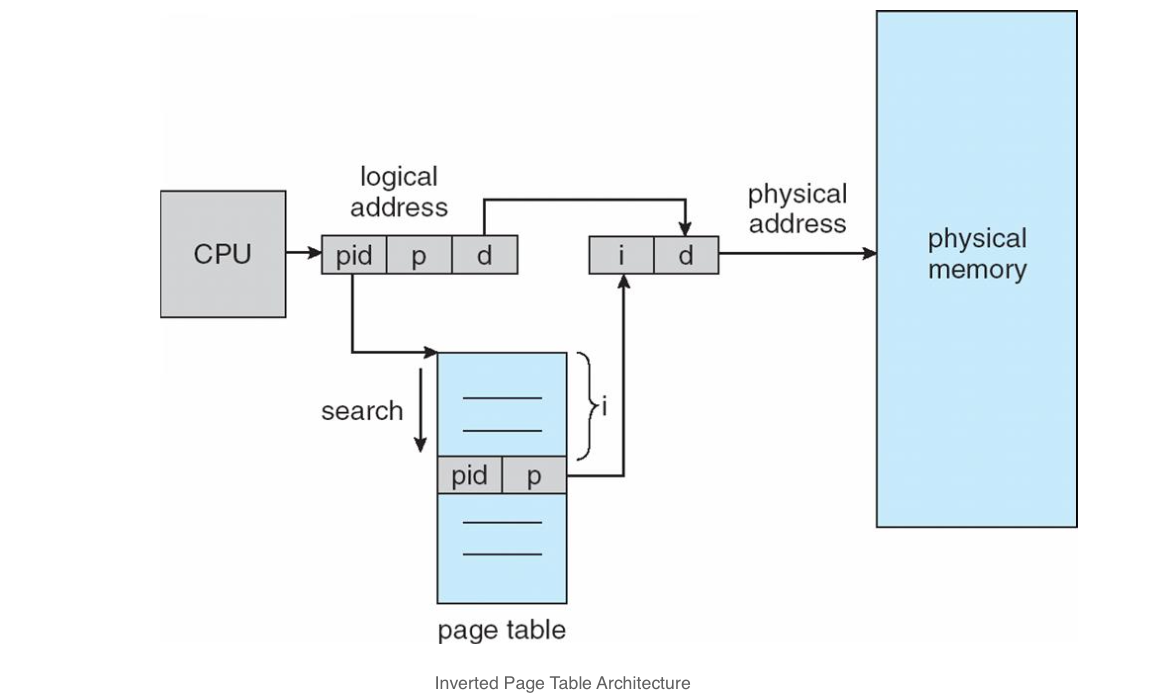
Inverted page tables
page table에 프로세스 정보를 추가해 하나의 통합된 page table로 물리 메모리에 접근하는 방법이다. 메모리는 적게 차지하지만 검색이 오래걸려 hash table과 같이 사용하는 것이 좋다.
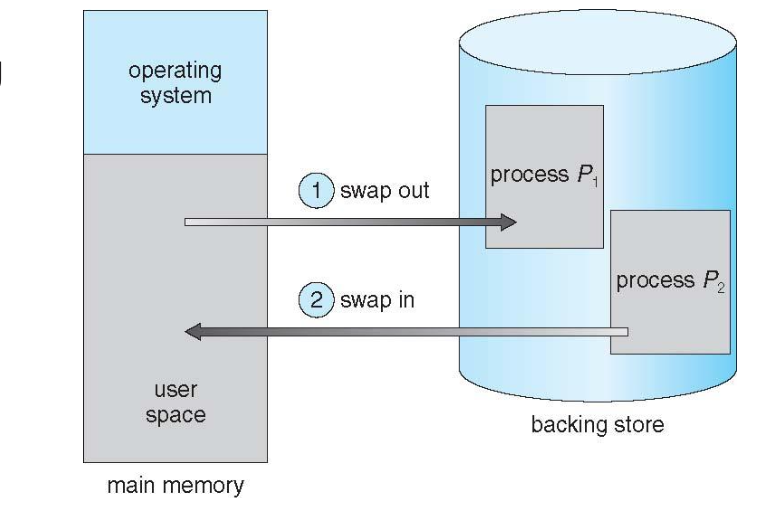
Swapping
현재 중요하지 않은 프로세스를 backing store에 중요한 프로세스를 메모리에 유동적으로 두는 것을 Swapping이라고 한다. 이에 대해서는 Virtual Memory에서 더 자세하게 다룰 것이다.