JPA 쿼리 최적화
본 글에서는 지연로딩, N+1을 이용하여 쿼리 최적화를 적용시키는 내용을 정리했습니다.😀
경우1: 조회의 조건으로 쓰일 id를 받았을 경우
실제 개신시킨 API를 예시로 보겠습니다.
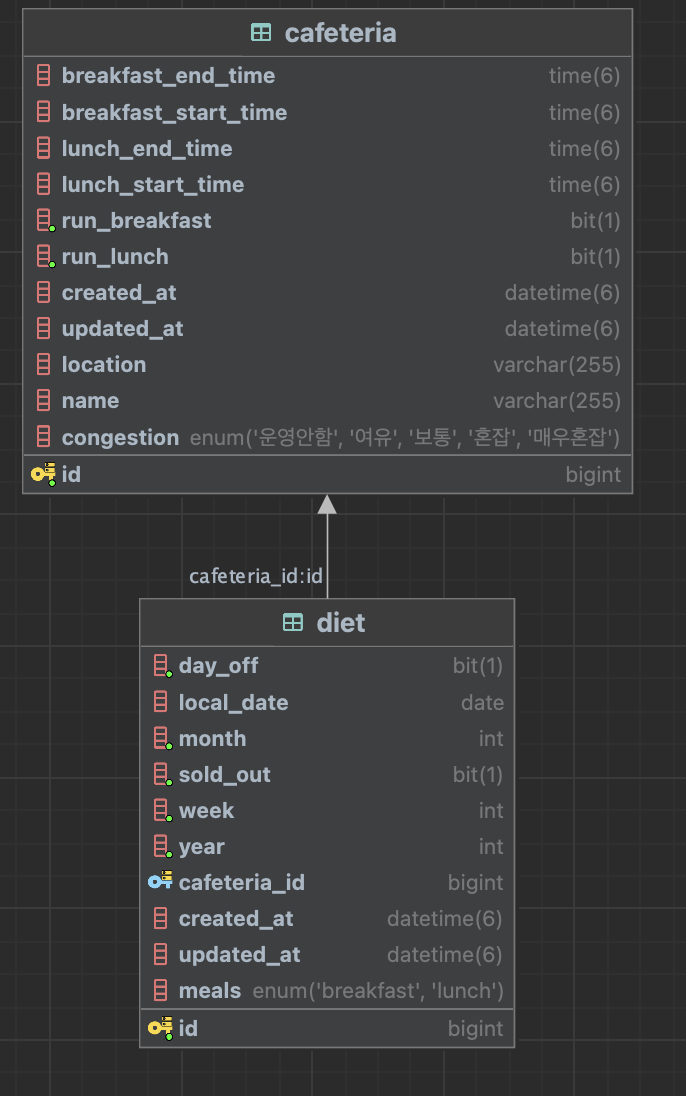
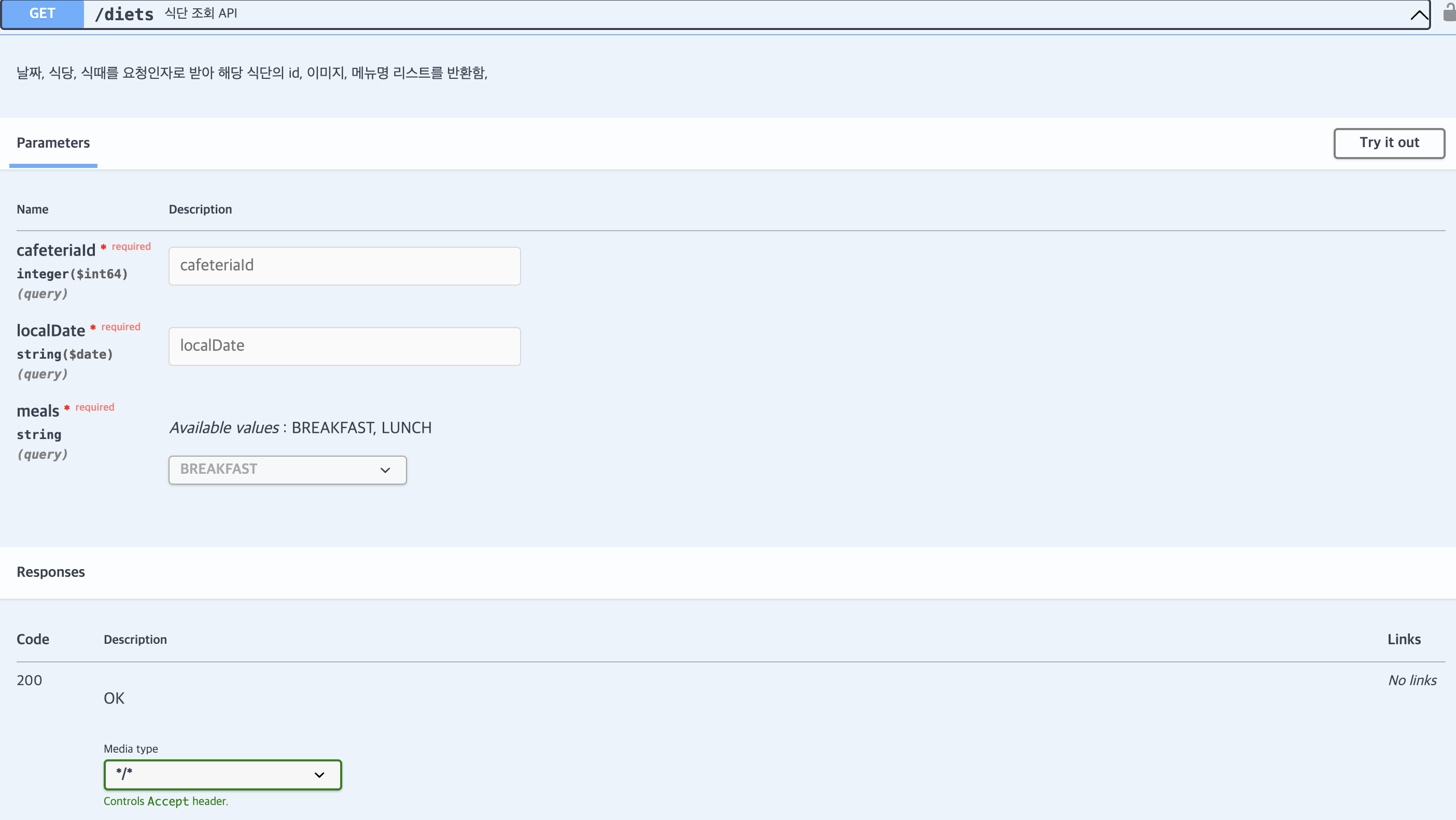
식단은 식당의 id를 외래키로 가지고 있습니다. 특정 식당의 식단을 가져오고 싶을 때 Spring Data JPA의 메서드를 통해 쿼리를 만든다면
1
Diet findByCafeteria(Cafeteria cafeteria)
이런식으로 만들 수 있겠죠?
하지만 그러기 위해서는 cafeteria객체가 필요한데 이를 요청에서 직접 받을 수는 없으니 위 예시 처럼 cafeteria의 id값을 받을겁니다. 그럼 식단을 조회하기 이전에 id값을 통해서 Cafeteria를 가져올 수 있고, 이를 위 메서드 인자로 넣어 조회하면 됩니다.
그런데,
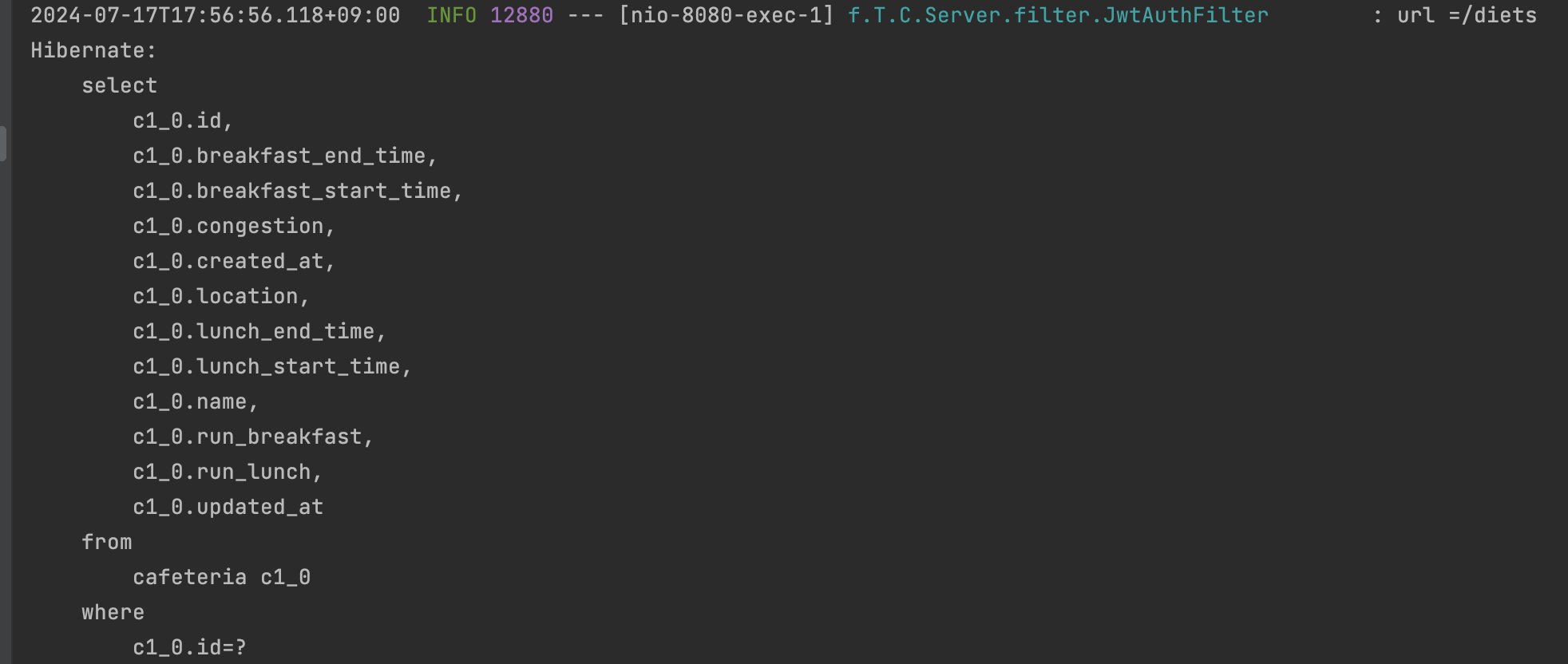
이 과정에서 사용하지도 않을 cafeteria 정보를 가져오는 불필요한 Select 쿼리가 생깁니다.. 🙁 이를 어떻게 해결할 수 있을까요?
프록시 객체와 지연로딩
이는 프록시 객체를 통해서 해결할 수 있습니다! findById(Long id)를 통해서 실제 정보가 매핑된 객체를 가져올 수도 있지만 getReferenceById(Long id)를 통해서 프록시 객체를 가져올 수도 있습니다.
이렇게 가져온 프록시 객체는 실제 값에 접근을 하기 전에는 Select문을 날리지 않고, 객체를 식별할 수 있는 최소 정보인 id를 가지고 있기 때문에 쿼리를 날리지 않고 where문의 객체로서 대신 사용할 수 있습니다.
물론 굳이 객체를 이용하지 않고 네이티브 쿼리를 이용해도 해결할 수 있는 부분이긴 합니다만.. 😅 쿼리 문자열에 비해 더 안정적으로 쿼리를 생성할 수 있다는 장점이 있으니 이렇게 객체 패러다임을 유지하며 해결하는 것도 좋은 방법이라고 생각합니다.
경우2: N+1 문제
이도 먼저 예시 상황을 보겠습니다.

아래는 해당 메서드가 실행되어 생성된 쿼리 로그 입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2024-07-17T17:57:01.532+09:00 INFO 12880 --- [nio-8080-exec-4] f.T.C.Server.filter.JwtAuthFilter : url =/diets
Hibernate:
select
d1_0.id,
d1_0.cafeteria_id,
d1_0.created_at,
d1_0.day_off,
d1_0.local_date,
d1_0.meals,
d1_0.month,
d1_0.sold_out,
d1_0.updated_at,
d1_0.week,
d1_0.year
from
diet d1_0
where
d1_0.cafeteria_id=?
and d1_0.local_date=?
and d1_0.meals=?
Hibernate:
select
dp1_0.id,
dp1_0.created_at,
dp1_0.diet_id,
dp1_0.image_key,
dp1_0.updated_at
from
diet_photo dp1_0
where
dp1_0.diet_id=?
Hibernate:
select
mdl1_0.diet_id,
mdl1_0.id,
mdl1_0.created_at,
mdl1_0.menu_id,
mdl1_0.updated_at
from
menu_diet mdl1_0
where
mdl1_0.diet_id=?
Hibernate:
select
m1_0.id,
m1_0.cafeteria_id,
m1_0.created_at,
m1_0.is_main,
m1_0.like_count,
m1_0.menu_category_id,
m1_0.name,
m1_0.updated_at
from
menu m1_0
where
m1_0.id=?
음.. N+1문제를 설명하기에 아주 적합한 예시는 아니지만 천천히 왜 이런 쿼리들이 날아 갔는지를 알아보겠습니다. 이 부분은 DB스키마에 대한 설명이 필요한 부분이니 N+1 해결 방법만을 알고 싶은 분들은 넘어가도 좋을 것 같습니다.
쿼리 생성 설명
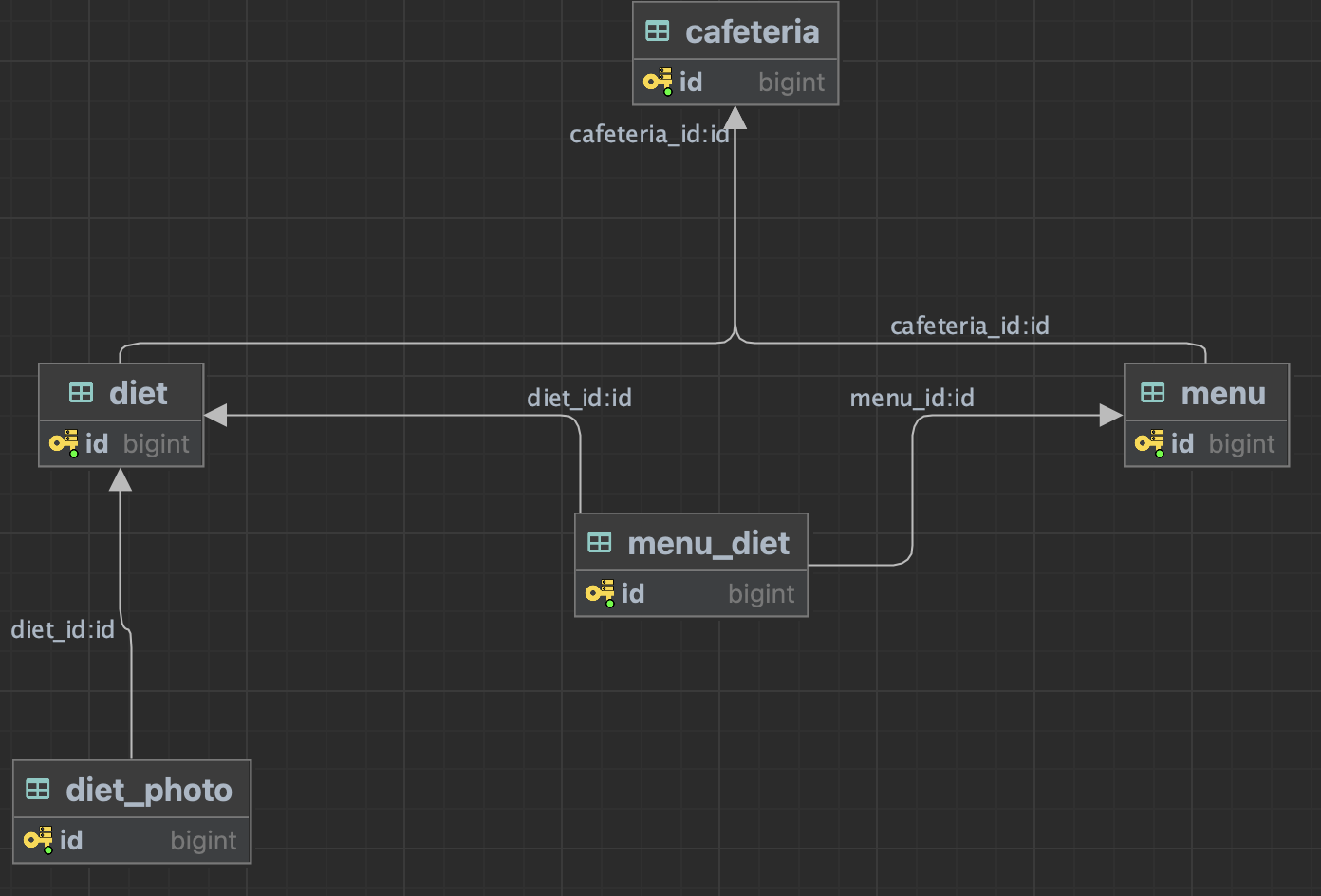
쿼리가 생성된 순서대로 보겠습니다.
diet의 속성인 cafeteria_id, local_date, meals를 조건으로 하는 Diet를 select쿼리
diet_photo에 대한 쿼리가 날아 갔습니다. 이는 diet가 부모엔티티로 OneToOne으로 매핑 됐으므로 자식 엔티티인 diet_photo가 Eager Loading되어 바로 날아갑니다.
아래와 같이 가져온 Diet에 대해서 MenuDiet, 그리고 Menu를 가져옵니다.
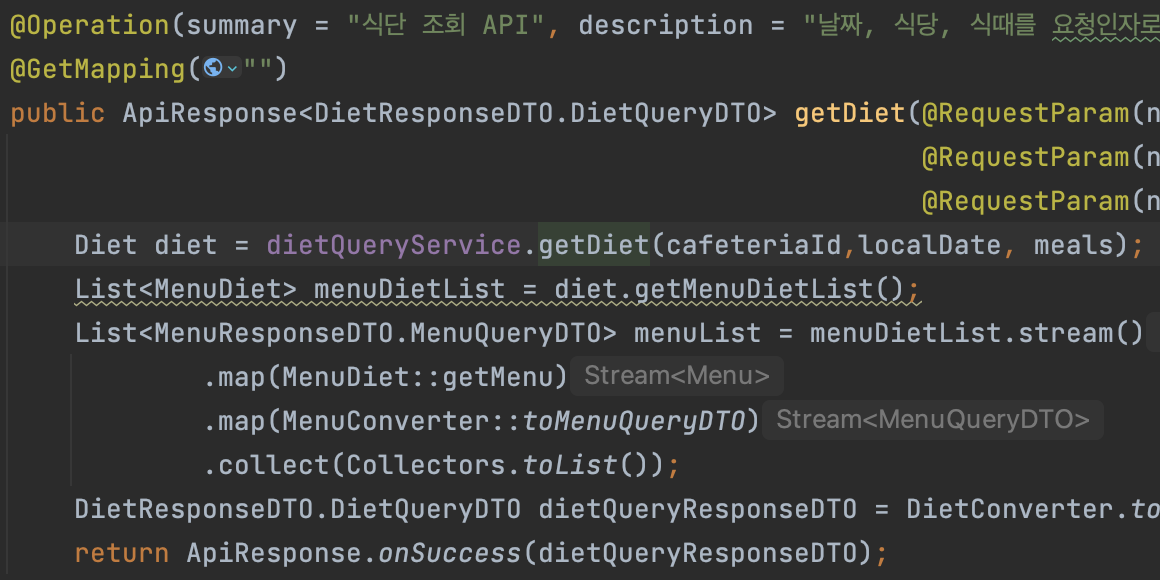
따라서 각각에 대한 쿼리가 날라가게 되고 추가되는 쿼리는 MenuDiet의 인스턴스 개수에 따라서 2N개씩 늘어나게 됩니다..!
여기서 2번과 3번의 쿼리는 연관관계로 인한 추가적인 쿼리가 발생한 것으로 N+1 문제이고 이를 해결해줄 필요가 있습니다. 특히 3번의 경우 menuDiet 인스턴스 개수의 2배로 선형적으로 증가하기 떄문에 성능을 고려하면 반드시 최적화 해주어야 합니다.
fetch join 적용시키기
N+1 문제를 해결하는 것은 여러 방법이 있습니다. fetch join나 @EntityGraph를 이용하여 원하는 테이블을 조인하여 가져오는 방법, @BatchSize로 where의 in 구문을 이용하는 법
diet는 diet_photo와는 OneToOne관계이기 때문에 쿼리가 선형적으로 증가하지는 않아 그대로 두었고
menu_diet와는 oneToMany 관계, menu_diet는 menu와 다시 ManyToOne 관계 이므로 fetch join을 사용해도 MultipleBageFetchException문제가 발생하지 않습니다.
그리고 식단에 매핑되는 메뉴 개수의 한계가 있기 때문에 join 연산이 크게 무겁지 않을 것이라 판단하여 fetch join을 사용했습니다.
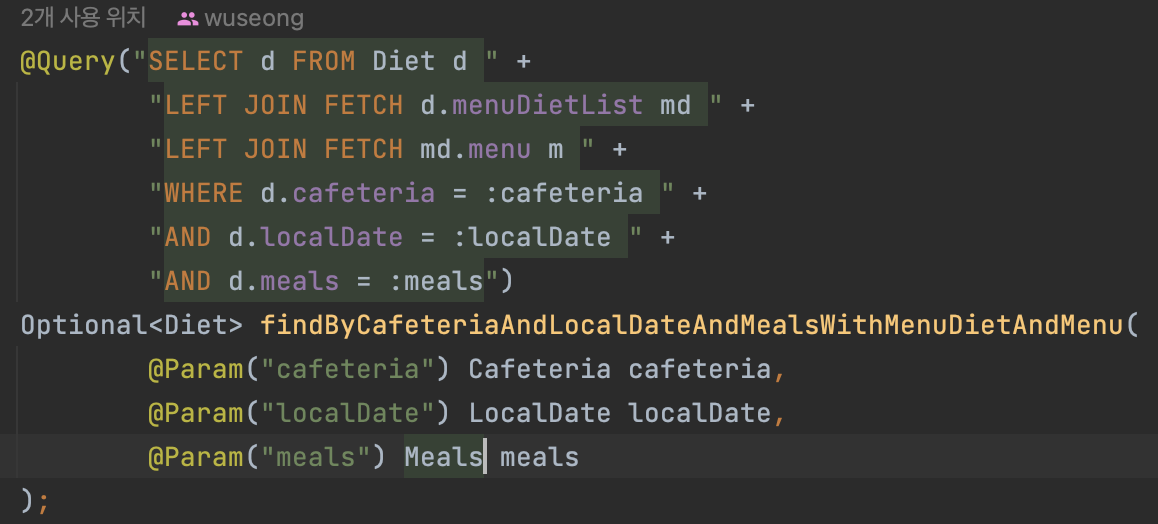

90~ 150 ms 정도 걸렸던 쿼리가

쿼리수는 10 → 2개로 평균 15ms 정도로 개선되었습니다! (1/10 수준) 👏
이후에 나머지 메서드에도 이를 적용시켜 유의미하게 성능을 향상시킬 수 있었습니다!
참고자료:
프록시
지연 로딩
하이버네이트 가이드