PostgreSQL Slow Query 7000배 개선하기: 실행 계획 분석과 LATERAL JOIN 활용

slow query를 발견하고 Postgresql의 실행 계획을 통해 문제점을 찾아 개선시킨 경험을 기록합니다.
배경
최근 프로젝트를 진행하면서 특정 화면의 로딩이 매우 오래 걸리는 것을 발견했다. 페이지를 로딩하는데 거의 4~5초 정도 걸리는 듯 했다. 초반에는 이러지 않았지만, 데이터가 쌓이면서 API 응답 속도가 느려진 듯 하다.
해당 API에서 접근하는 DB 정보는 대략적으로 다음과 같다.
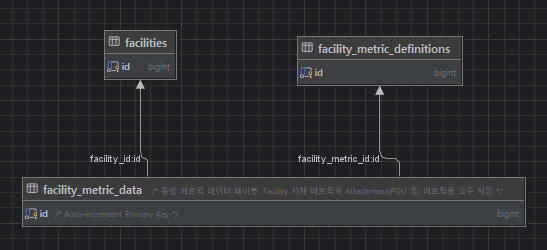
핵심 테이블 구조:
facilies: 모니터링 대상 설비 정보 (예: CRAC, 서버, UPS 등)facility_metric_definitions: 측정 가능한 메트릭 정의 (예: 온도, 습도, 전력 등)facility_metric_data: 실제 측정된 데이터 (시계열 데이터, n분마다 수집)
데이터 특징:
- 하나의 설비(facility)는 여러 메트릭을 가짐
- 각 메트릭은 시간에 따라 계속 누적됨 (시계열)
병목 지점 파악
API 내부 동작은 cpu-burst 하진 않고, DB에서 읽어오는 일반적인 조회 기능을 가진 API 였기 때문에 DB쪽에서 데이터를 읽어 오면서 생긴 병목일 것이라고 예상했다.
쿼리 성능 측정
DB에서 병목이 되는 지점을 정확히 알기 위해서 slow query를 먼저 알고자 했다. DB에서도 직접 알 수 있겠지만 해당 프로젝트는 Nest.js + TypeORM을 사용하고 있기 떄문에 TypeORM의 Data Source Options를 이용하여 서버 로그에서 쿼리 성능에 대한 정보를 편하게 보고자 했다.
1
2
3
4
5
6
export const databaseConfig: TypeOrmModuleOptions = {
...
logger: 'advanced-console',
maxQueryExecutionTime: 1000,
...
}
쿼리에 대한 실행 시간 정보까지 알 수 있는 'advanced-console'를 logger로 설정하고(디폴트 옵션이라 설정 생략 가능) maxQueryExcutionTime 값을 1000(ms)으로 두면 1초 이상이 걸리는 slow 쿼리에 대해 기록한다.
1
2
3
4
5
6
7
8
9
10
11
query is slow:
SELECT DISTINCT ON (data.facility_metric_id)
...
data.labels
FROM facility_metric_data data
JOIN facility_metric_definitions def ON data.facility_metric_id = def.id
WHERE data.facility_id = $1
AND def.facility_type = $2
ORDER BY data.facility_metric_id, data.measured_dt DESC
-- PARAMETERS: ["29","CRAC"]
execution time: 2338
특정 장비에 대해서 수집되는 메트릭에 대해서 최근 값 1개만 가지고 오는 쿼리이다.
데이터 확인
유독 id가 28, 29인 대상에 대해서 성능 저하가 발생하여 데이터를 확인해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
SELECT facility_id, COUNT(*)
FROM facility_metric_data
WHERE facility_id IS NOT NULL
GROUP BY facility_id;
/* 결과
facility_id | count
------------|----------
28 | 1,163,550
29 | 1,040,604
30 | 약 수천 개
*/
데이터가 많이 쌓인 것은 확인이 됐다. 이제 실제로 쿼리에서 이 데이터를 조회할 때 어떤 과정으로 조회하는지를 알아보자.
실행 계획 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT DISTINCT ON (data.facility_metric_id)
data.facility_id AS "facilityId",
data.facility_metric_id AS "facilityMetricId",
def.id AS "defId",
def.name AS "metricName",
def.data_type AS "dataType",
def.unit,
def.facility_type AS "facilityType",
def.description,
data.value_num AS "valueNum",
data.value_int AS "valueInt",
data.value_bool AS "valueBool",
data.value_text AS "valueText",
data.value_json AS "valueJson",
data.measured_dt AS "measuredDt",
data.received_dt AS "receivedDt",
data.labels
FROM facility_metric_data data
JOIN facility_metric_definitions def
ON data.facility_metric_id = def.id
WHERE data.facility_id = 29
AND def.facility_type = 'CRAC'
ORDER BY data.facility_metric_id, data.measured_dt DESC;
실행 계획 결과:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Unique (cost=19128.82..249348.63 rows=13 width=551) (actual time=366.327..2319.447 rows=7 loops=1)
" Output: data.facility_id, data.facility_metric_id, def.id, def.name, def.data_type, def.unit, def.facility_type, def.description, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.measured_dt, data.received_dt, data.labels"
" Buffers: shared hit=214138 read=707011, temp read=30459 written=30511"
-> Incremental Sort (cost=19128.82..249235.21 rows=45371 width=551) (actual time=366.325..2273.731 rows=1040604 loops=1)
" Output: data.facility_id, data.facility_metric_id, def.id, def.name, def.data_type, def.unit, def.facility_type, def.description, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.measured_dt, data.received_dt, data.labels"
" Sort Key: data.facility_metric_id, data.measured_dt DESC"
Presorted Key: data.facility_metric_id
Full-sort Groups: 7 Sort Method: quicksort Average Memory: 54kB Peak Memory: 54kB
Pre-sorted Groups: 7 Sort Method: external merge Average Disk: 66336kB Peak Disk: 66336kB
" Buffers: shared hit=214138 read=707011, temp read=30459 written=30511"
-> Nested Loop (cost=0.57..245997.94 rows=45371 width=551) (actual time=0.096..1687.899 rows=1040604 loops=1)
" Output: data.facility_id, data.facility_metric_id, def.id, def.name, def.data_type, def.unit, def.facility_type, def.description, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.measured_dt, data.received_dt, data.labels"
Buffers: shared hit=214135 read=707011
-> Index Scan using facility_metric_definitions_pkey on public.facility_metric_definitions def (cost=0.14..12.56 rows=1 width=112) (actual time=0.031..0.045 rows=9 loops=1)
" Output: def.id, def.name, def.data_type, def.unit, def.description, def.created_at, def.updated_at, def.facility_type, def.attachment_type"
Filter: (def.facility_type = 'CRAC'::facility_type)
Rows Removed by Filter: 15
Buffers: shared hit=1 read=1
-> Index Scan using ix_fmd_facility_metric_time on public.facility_metric_data data (cost=0.43..245147.75 rows=83763 width=439) (actual time=0.015..172.984 rows=115623 loops=9)
" Output: data.id, data.facility_id, data.attachment_id, data.facility_metric_id, data.measured_dt, data.labels, data.labels_hash, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.received_dt"
Index Cond: ((data.facility_id = 29) AND (data.facility_metric_id = def.id))
Buffers: shared hit=214134 read=707010
Planning:
Buffers: shared hit=87 read=2
Planning Time: 1.193 ms
Execution Time: 2321.874 ms
이 실행 계획을 한번 해석해보자. 실행 계획을 순서대로 읽으려면 아래에서 부터 읽으면 된다.
쿼리의 목적: CRAC 타입의 한 설비가 가질 수 있는 모든 메트릭의 최신 값을 가져오는 것
실행 과정:
facility_metric_definitions에서facility_type이 ‘CRAC’인 행을 찾는다. (index scan, 애초에 정의 자체는 수가 많지 않아 성능 이슈 없음)facility_metric_data테이블에서 각metric_definitions마다 매핑되는 행을 찾는다. (index scan, heap fetch 하는 과정에서 약 77%는 disk read까지 일어남, bad)ORDER BY data.facility_metric_id, data.measured_dt DESC에 의하여 추가적인 정렬을 수행한다. (이 때도 데이터가 많은 케이스에 대해서 메모리가 부족하여 external merge가 실행됨, bad)
결론적으로 봤을 때, 문제가 많아 보이는 쿼리이다. 문제가 되는 지점들을 좀 더 정확히 파악해보자.
메모리 설정 확인
지금 상황을 봤을 때, heap fetch를 할 때, 그리고 추가적인 정렬을 할 때 메모리가 부족해보인다. 그럼 두 상황에서 메모리를 충분하게 사용할 수 있도록 하려면 어떤 설정을 해야할까?
Postgresql 메모리 구조
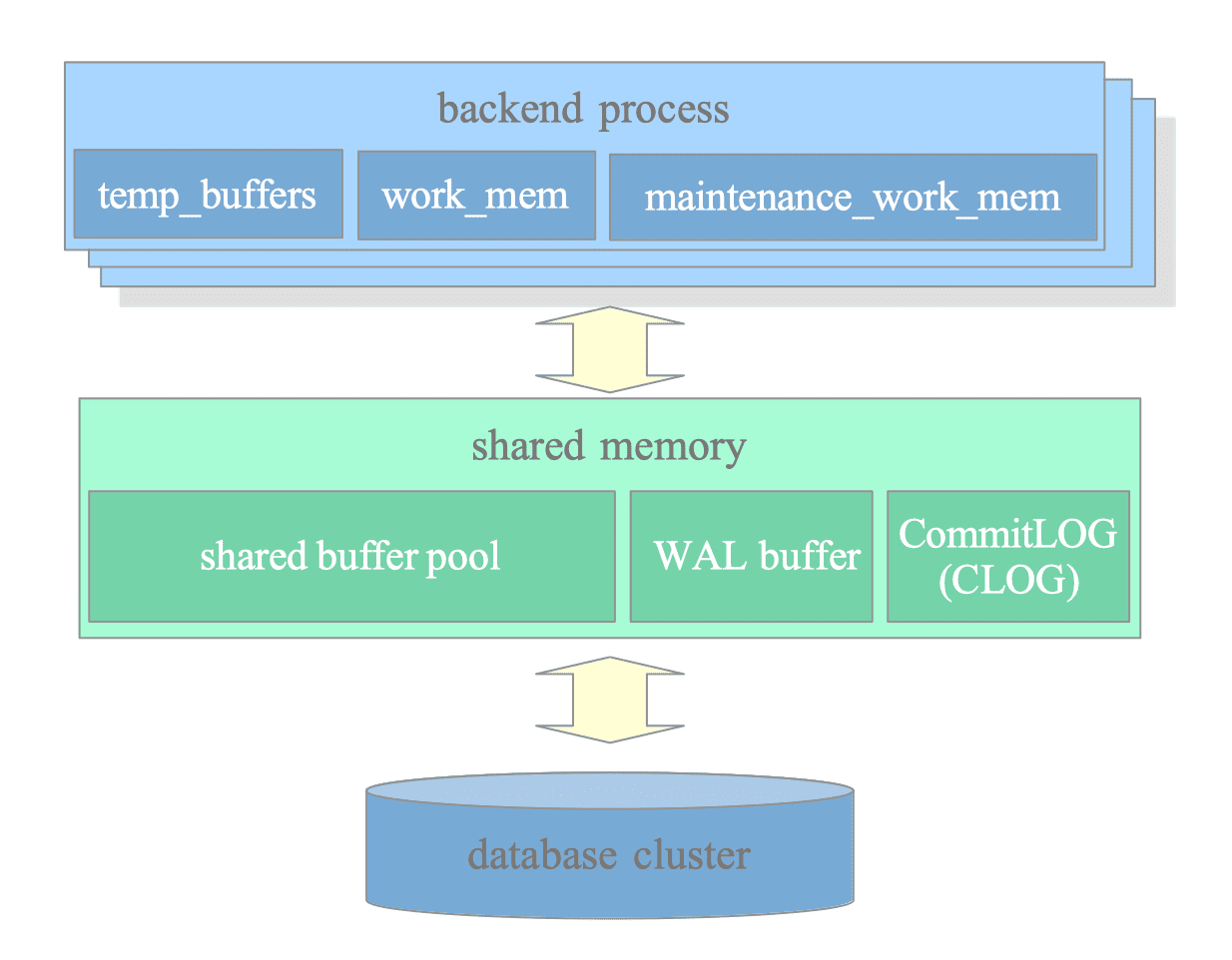
Postgresql 메모리 구조는 크게 backend 프로세서에 할당되는 local memory와 Postgesql server 자체에 할당되는 공유 메모리로 나뉜다. 위 실행계획에서 사용된 정렬 시에 사용하는 메모리, heap fetch에 사용하는 메모리는 아래와 같다.
shared_buffers
- 테이블/인덱스 페이지를 디스크에서 읽을 때
- 테이블/인덱스 페이지에 쓸 때 (INSERT/UPDATE/DELETE)
work_mem
- ORDER BY (정렬)
- GROUP BY (집계 전 정렬 또는 해시)
- DISTINCT (중복 제거)
- Hash Join
- Merge Join (정렬 필요 시)
- Bitmap 연산 (Bitmap Heap Scan)
- CTE, 서브쿼리의 Materialize
- Window Functions
따라서 heap fetch 시에 메모리가 부족하다면, 테이블 페이지를 가져올 때 사용하는 shared_buffers를,
정렬 시 사용하는 메모리가 부족하다면, work_mem을 설정하면 된다.
work_mem 설정
먼저, 정렬 시에 메모리가 부족하여 disk read를 하는 external merge를 사용했기 때문에 기존의 work_mem이 어느정도인지 먼저 확인해보자.
1
SHOW work_mem;
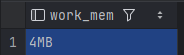
4MB였다. disk read가 일어나지 않도록 work_mem을 충분히 늘리고 테스트 해보자.
work_mem 설정에 따른 성능 테스트
work_mem = 200MB로 설정하고(200MB가 적당한 크기는 아닐 수 있지만, 성능 비교를 위해) Incremental Sort 부분 실행 계획만을 비교해 봤을 때:
기존 4MB일 때의 실행 계획:
1
2
3
4
5
Incremental Sort (actual time=362.663..2239.029 rows=1040611 loops=1)
Full-sort Groups: 7 Sort Method: quicksort Average Memory: 54kB Peak Memory: 54kB
Pre-sorted Groups: 7 Sort Method: external merge Average Disk: 66336kB Peak Disk: 66336kB
...
-> Nested Loop (actual time=0.136..1672.021 rows=1040611 loops=1)
- Incremental Sort 총 시간: 2239 ms
- 하위 Nested Loop 시간: 1672 ms
- Sort 자체 시간: ~567 ms
200MB 때의 실행 계획:
1
2
3
4
5
6
Incremental Sort (actual time=386.309..2654.849 rows=1040611 loops=1)
Presorted Key: data.facility_metric_id
Full-sort Groups: 7 Sort Method: quicksort Average Memory: 54kB Peak Memory: 54kB
Pre-sorted Groups: 7 Sort Method: quicksort Average Memory: 74724kB Peak Memory: 74724kB
...
-> Nested Loop (actual time=31.368..2258.785 rows=1040611 loops=1)
- Incremental Sort 총 시간: 2679 ms
- 하위 Nested Loop 시간: 2283 ms
- Sort 자체 시간: ~396 ms
567ms → 396ms (약 30% 성능 개선)이 일어나는 걸 볼 수 있다.
work_mem이 증가하면서 Nested Loop의 실행계획이 달라져서 오히려 성능이 감소되는건 나중에 따로 다뤄볼 예정이다..
shared buffers 설정? 그 이전에
heap fetch 과정에서 메모리 부족으로 인해서 disk I/O가 발생했으니 그만큼 shared_buffers를 늘려줘야할까..?
그 이전에 먼저 load한 페이지들이 모두 필요한지부터 확인해봐야한다.
지금 실행 계획을 다시 보면 join을 통해서 1,040,611개의 행을 가져오고 있지만 마지막에 다 거치고 남은 결과는 7개밖에 채 되지 않는다. 즉, load만 하고 버려지는 행이 1,040,604개나 된다는 것이다.
이 쿼리의 목적을 다시 한번 생각해보자.
facility_metric_data 테이블에서 최종적으로 가져올 데이터는 최신 데이터이기 때문에 애초에 100만개가 넘는 행을 모두 join 하는 것 자체가 비효율이다.
이 비효율을 개선할 수 있는 방법은 매우 다양할 것이다.
- Join하기 이전에 서브쿼리를 통해 각 메트릭별 최신 데이터만 가져와서 줄일 수도 있을 것이고
- CTE를 통해 사전 필터링을 거칠 수도 있고
- 처음부터 최신 쿼리만 가져오는 Materialized View를 만들 수도 있을 것이다
그러던 중 가장 적합해 보이는 Lateral 문법을 알게 되었고 이 방법이 가장 효율적일 것이라고 생각했다.
해결 방법
Lateral
이 문법은 Join과 같이 쓰이며 서브쿼리가 외부 쿼리의 열을 참조할 수 있게 하여, 각 outer table의 행을 참조하여 서브쿼리를 실행할 수 있게 해주는 문법이다.
이 문법이 지금 상황에서 최적인 이유는 현재 join시에 outer table의 행 수가 적고, inner table의 행 수가 압도적으로 많다. 그런데 실질적인 join하여 로드된 inner table 페이지는 사용되지 않고 버려진다.
따라서 각 outer table의 한 행 마다 inner table의 최신 정보인 1개의 행만 읽고 멈출 수 있다.
그럼 실제로 Lateral 문법을 적용하여 join 성능을 개선시키고 실제 실행 계획을 보고 얼마나 어떻게 개선 됐는지를 확인해 보자.
적용 결과
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT
def.id as "defId",
def.name as "metricName",
def.data_type as "dataType",
def.unit,
def.facility_type as "facilityType",
def.description,
latest.facility_id as "facilityId",
latest.facility_metric_id as "facilityMetricId",
latest.value_num as "valueNum",
latest.value_int as "valueInt",
latest.value_bool as "valueBool",
latest.value_text as "valueText",
latest.value_json as "valueJson",
latest.measured_dt as "measuredDt",
latest.received_dt as "receivedDt",
latest.labels
FROM facility_metric_definitions def
LEFT JOIN LATERAL (
SELECT *
FROM facility_metric_data data
WHERE data.facility_id = 29
AND data.facility_metric_id = def.id
ORDER BY data.measured_dt DESC
LIMIT 1
) latest ON true
WHERE def.facility_type = 'CRAC';
개선된 쿼리의 실행 계획:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Nested Loop Left Join (cost=0.43..4.70 rows=1 width=552) (actual time=0.128..0.377 rows=9 loops=1)
" Output: def.id, def.name, def.data_type, def.unit, def.facility_type, def.description, data.facility_id, data.facility_metric_id, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.measured_dt, data.received_dt, data.labels"
Buffers: shared hit=19 read=16
-> Seq Scan on public.facility_metric_definitions def (cost=0.00..1.30 rows=1 width=112) (actual time=0.019..0.033 rows=9 loops=1)
" Output: def.id, def.name, def.data_type, def.unit, def.description, def.created_at, def.updated_at, def.facility_type, def.attachment_type"
Filter: (def.facility_type = 'CRAC'::facility_type)
Rows Removed by Filter: 15
Buffers: shared hit=1
-> Limit (cost=0.43..3.38 rows=1 width=488) (actual time=0.036..0.036 rows=1 loops=9)
" Output: NULL::bigint, data.facility_id, NULL::bigint, data.facility_metric_id, data.measured_dt, data.labels, NULL::bytea, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.received_dt"
Buffers: shared hit=18 read=16
-> Index Scan using ix_fmd_facility_metric_time on public.facility_metric_data data (cost=0.43..230711.40 rows=78082 width=488) (actual time=0.035..0.035 rows=1 loops=9)
" Output: NULL::bigint, data.facility_id, NULL::bigint, data.facility_metric_id, data.measured_dt, data.labels, NULL::bytea, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.received_dt"
Index Cond: ((data.facility_id = 29) AND (data.facility_metric_id = def.id))
Buffers: shared hit=18 read=16
Planning Time: 0.545 ms
Execution Time: 0.461 ms
캐시가 적용되지 않아서 disk read를 했음에도 훨씬 성능이 개선된 모습을 볼 수 있었다. 방금 실행을 통해 캐싱 되었을 테니 다시 한번 실행해서 ix_fmd_facility_metric_time 캐싱이 적용된 결과만 봐보자.
1
2
3
4
5
6
7
8
Nested Loop Left Join (cost=0.43..4.70 rows=1 width=552) (actual time=0.070..0.221 rows=9 loops=1)
...
-> Index Scan using ix_fmd_facility_metric_time on public.facility_metric_data data (cost=0.43..230711.40 rows=78082 width=488) (actual time=0.018..0.018 rows=1 loops=9)
" Output: NULL::bigint, data.facility_id, NULL::bigint, data.facility_metric_id, data.measured_dt, data.labels, NULL::bytea, data.value_num, data.value_int, data.value_bool, data.value_text, data.value_json, data.received_dt"
Index Cond: ((data.facility_id = 29) AND (data.facility_metric_id = def.id))
Buffers: shared hit=34 <- 모두 shared memory에서 가져옴
Planning Time: 0.551 ms
Execution Time: 0.287 ms
결론적으로 실행시간이 2200ms ~ 2300ms 걸리던 쿼리가 0.287ms로 수천 배 이상 빨라졌다.
느낀점
기존에 느리게 실행됐던 쿼리가 어떻게 실행되고, 실행 계획을 읽어보며 어느 부분에서 비효율이 생기는지 이해하니 어떤 방법으로 개선을 시키는 것이 더 좋을지가 명확하게 보이는 듯 했다.
기존의 쿼리가 워낙 비효율적인 부분도 있었지만, 그래도 쿼리 튜닝을 통해 API 성능을 개선시켜 페이지 로딩이 빨라지는 모습을 보니 뿌듯함도 같이 느껴졌다.
실행 계획을 분석하면서 기존에 잘 몰랐던 Postgresql 메모리 구조나 join, sort 구현 방법 등에 대해서도 깊게 이해하는 계기가 되어 좋은 경험이라고 생각한다.
앞으로도 slow 쿼리를 발견할 시에는 잘 해결할 수 있을 것 같다.
참고자료
- TypeORM Configuration
- PostgreSQL Internals
- PostgreSQL SELECT Documentation
- seungtaek-overflow - [PG] 쿼리 실행 계획 분석하기 - Table Scan
P.S. GPT 썸네일 이미지 잘 만드는 듯 하면서 뭔가 촌스럽네..